MemOp: Enhancing Software Engineering Through Closed-Loop Memory Optimization
Abstract
Large language models have produced powerful software-engineering (SE) agents that can navigate complex codebases and resolve real-world issues. However, these agents remain fundamentally episodic: they fail to retain, refine, and reuse experiences across tasks, repeatedly reconstructing context from scratch and reproducing similar mistakes. Even when memory is added, there is no principled, task-agnostic notion of memory utility, making memory-augmented systems hard to evaluate rigorously or generalize across agents and settings.
We introduce MemOp, a closed-loop framework for memory augmentation in SE agents. MemOp grounds memory utility in validated downstream impact, establishing utility as both a task-agnostic evaluation benchmark and an annotation-free optimization signal. Under complementary single-episode and cross-episode memory augmentation, MemOp consistently improves SE agents across settings, with absolute gains of up to ↑5.25% in success rate and ↑4.63% in resolve efficiency, while reducing computational cost by ≥9.79%.
Motivation & Challenges
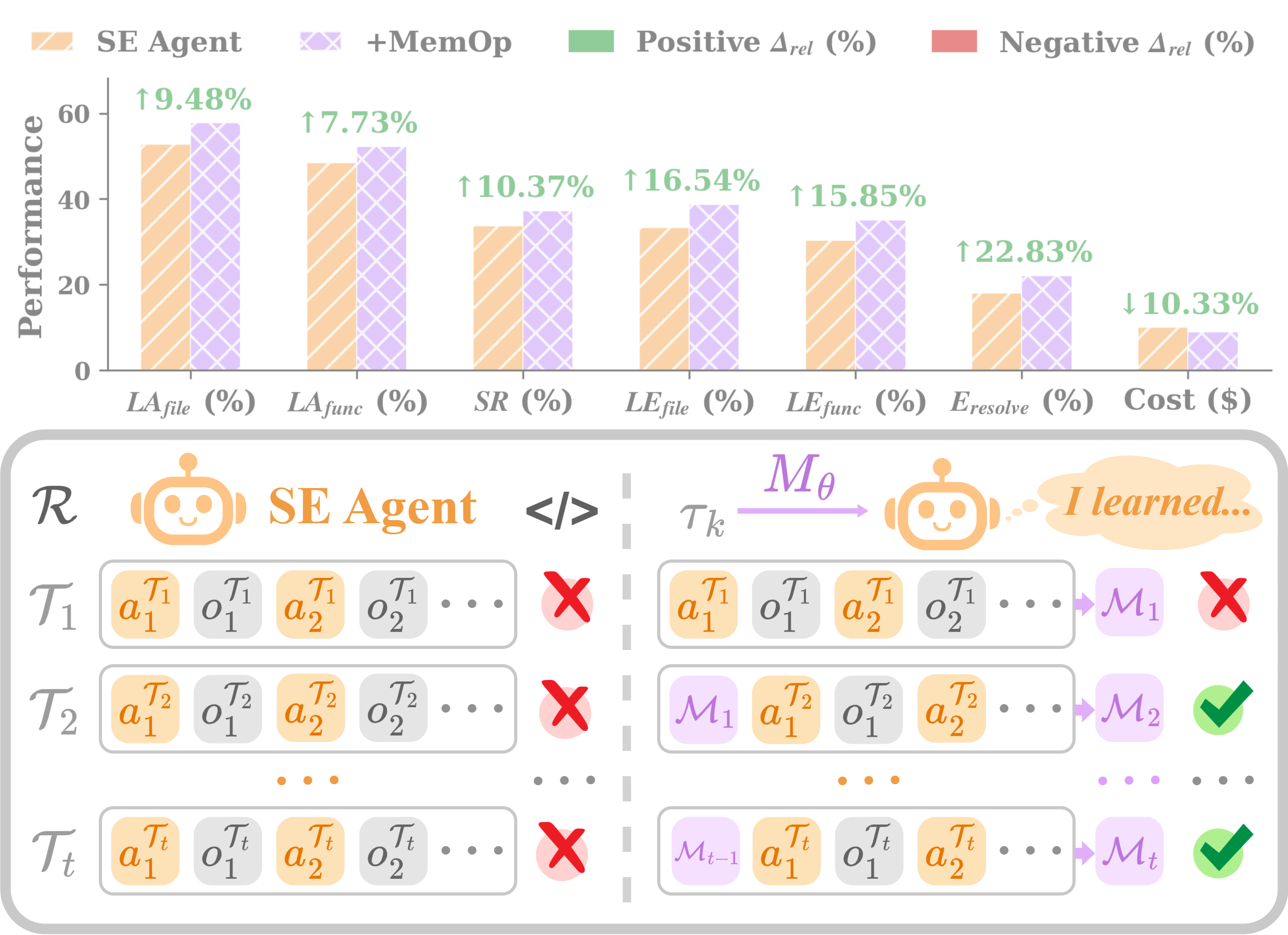
Figure 1. Memory-Augmented Software Engineering. Compared with a no-Mθ SE agent (left), MemOp (right) equips SE agents with adaptively distilled memories to better tackle dynamic real-world SE challenges.
Despite their capability, SE agents fail to develop an adaptive and evolvable mental model across tasks. When solving repository-level issues, they reconstruct context from scratch, rediscover codebase structure, repeat ineffective implementation strategies, and overlook transferrable knowledge. This is not a fundamental capability limit, but stems from the absence of principled memory mechanisms that continuously distill experience into reusable knowledge.
Challenges To Address
① Measuring Memory Utility
Existing memory-augmented agents lack a principled, task-agnostic definition of whether a given memory actually helps downstream performance. Without it, memory quality is impossible to evaluate rigorously or transfer across agents.
② Optimizing Toward Utility
Prior work relies on task-specific heuristics, complex architectures, or human-curated annotations to refine memory. None convert utility into a learning signal — leaving memory design hand-tuned and brittle.
③ Generalizing Across Settings
Useful memory must work across diverse repositories, SE agents, and reflection regimes — from one-shot generation to long-horizon evolution across episodes.
Preliminary Study: Where SE Agents Fail
To ground the design of MemOp, we manually examine the complete trajectories of 50 SE failures (SR = 0%) by a GPT-4o-mini–powered agent and identify seven recurring failure patterns. Repository-structure misinterpretation and long-context repetition dominate — both stem from the agent's inability to distill and remember codebase structure and prior actions.
Figure 6. Seven recurring failure patterns in SE agent problem-solving: repository structure, repetition, reasoning, coding, execution, inconsistency, hallucination.
Memory Utility: If It Doesn't Help, It Doesn't Count
A Principled, Outcome-Grounded Definition of Memory Utility
A memory is useful if and only if it demonstrably improves SE agent performance on downstream tasks — measured against a no-memory baseline across ten multi-dimensional metrics covering effectiveness and efficiency.
Figure 2. Memory Utility through performance-grounded memory evaluation and trajectory-level rejection sampling.
Memory Acceptance Criterion
Given a candidate memory Mj generated from a trajectory τk on task Tk, we measure the performance change Δi(Mj) for each of NQ=10 metrics by comparing memory-augmented problem-solving against the no-memory baseline. Mj is accepted as high-quality iff:
That is, a memory must not hurt any metric and must improve at least one. Candidates failing this criterion are rejected.
A Dual-Role Harness
① Evaluation Benchmark
The acceptance criterion serves as a rigorous, task-agnostic evaluation of any memory, independent of the agent that produces it.
② Optimization Signal
The same criterion converts each candidate into a optimization signal, enabling closed-loop memory optimization without external annotation.
Preliminary: Which Memory Structure Helps Most?
We benchmark nine memory representations on 30 SWE-Bench-Verified instances (GPT-4o-mini agent + GPT-4o memory model, 20-turn budget). All structures can help over no-memory baseline, while markdown structure delivers the largest gains, especially on localization accuracy and efficiency, which are essential prerequisites for SE problem-solving.
| Memory Structure | SR | LA(1)file | LA(1)func | LE(1)file | LE(1)func |
|---|---|---|---|---|---|
| × (no memory) | 0.00 | 56.57 | 16.67 | 35.50 | 11.00 |
| ✓ String | 0.00 | 63.33 ↑6.76 | 43.33 ↑26.66 | 41.85 ↑6.35 | 31.65 ↑20.65 |
| ✓ Dictionary | 0.00 | 76.67 ↑20.10 | 46.67 ↑30.00 | 50.35 ↑14.85 | 28.85 ↑17.85 |
| ✓ List | 0.00 | 53.33 ↓3.24 | 26.67 ↑10.00 | 42.00 ↑6.50 | 20.35 ↑9.35 |
| ✓ Tree | 0.00 | 60.00 ↑3.43 | 30.00 ↑13.33 | 43.00 ↑7.50 | 21.50 ↑10.50 |
| ✓ Graph | 0.00 | 66.67 ↑10.10 | 46.67 ↑30.00 | 46.50 ↑11.00 | 28.35 ↑17.35 |
| ✓ Python | 0.00 | 73.33 ↑16.76 | 40.00 ↑23.33 | 56.35 ↑20.85 | 33.00 ↑22.00 |
| ✓ Given | 0.00 | 60.00 ↑3.43 | 36.67 ↑20.00 | 42.65 ↑7.15 | 23.50 ↑12.50 |
| ✓ Discretionary | 0.00 | 63.33 ↑6.76 | 33.33 ↑16.66 | 45.15 ↑9.65 | 26.35 ↑15.35 |
| ✓ Ours (Memory.md) | 0.00 | 76.67 ↑20.10 | 50.00 ↑33.33 | 53.15 ↑17.65 | 29.65 ↑18.65 |
Take-away: memory structures that are easier for the SE agent to read and understand are also more effective. Memory.md wins on both localization accuracy and localization efficiency.
MemOp: Closed-Loop Memory Optimization
Two-Stage Training, One Validated Reward
Building on validated memory utility, MemOp trains a memory model Mθ through trajectory-based rejection sampling followed by two-stage finetuning — Stage I (SFT) acquires foundational memory-generation ability, Stage II (RL) optimizes directly toward downstream SE impact.
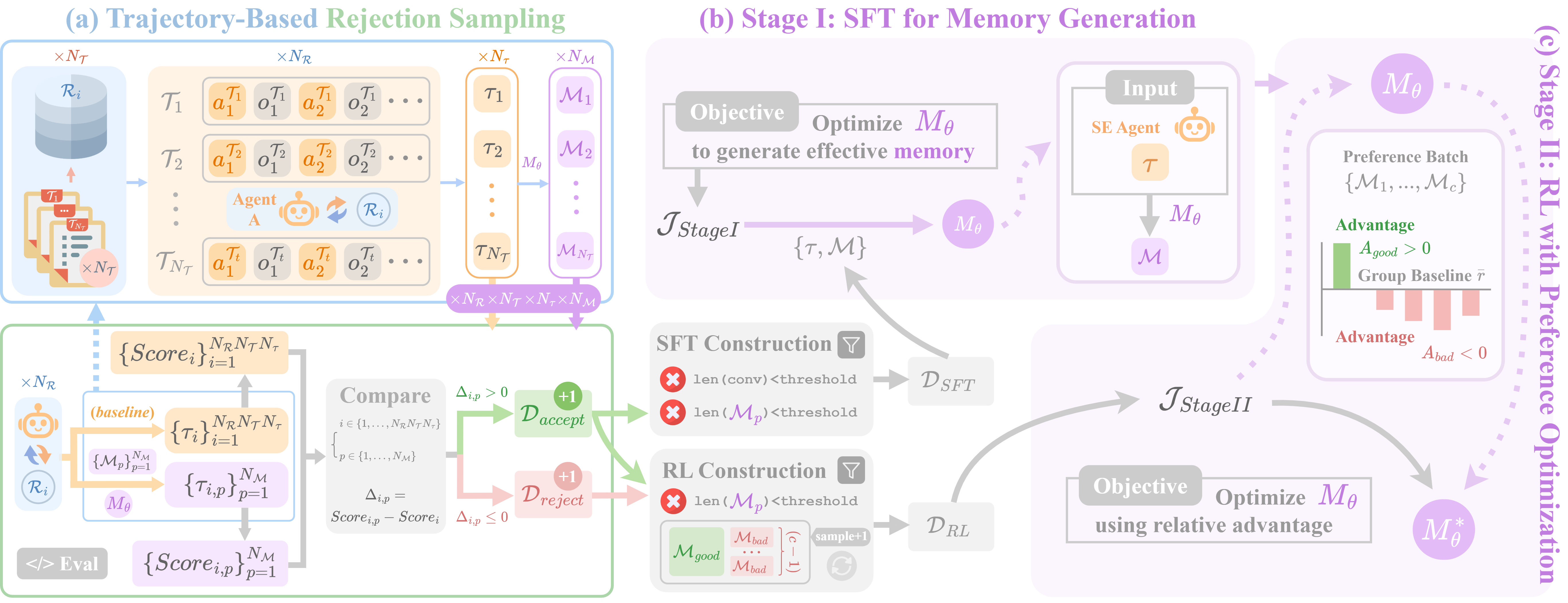
Figure 3. Memory Model Finetuning. Datasets are curated via trajectory-based rejection sampling; Mθ is finetuned through two-stage training (SFT and RL).
Two-Stage Memory Model Training
Stage I — Supervised Finetuning
Train Mθ on the accepted dataset DSFT to learn what an effective memory looks like:
JI = −𝔼(τ,M)∼DSFT [ log Pθ(M | τ, T, R) ]
This establishes the foundation for high-quality memory generation.
Stage II — RL with Validated Reward
Optimize Mθ with a reward grounded in measured downstream improvement, where ground-truth memory comes from Daccept and contrastive candidates from Dreject:
r(Mi) = (1 / NQ) Σℓ Δℓ(Mi)
Mθ is rewarded for memory that measurably improves the SE agent, penalized for memory that is redundant or harmful.
Two Evaluation Regimes
Single-Episode Generation
Mθ distills memory from a single completed trajectory, which is immediately reused to augment the agent. Validates the fundamental quality of MemOp's memory generation in isolation.
Cross-Episode Evolution
Memory evolves progressively across a sequence of tasks. Tests whether memory remains coherent, non-redundant, and increasingly useful as the agent encounters a growing diversity of tasks.
Experiments & Key Insights
Performance Overview
Table 1: Single-Episode Memory Augmentation
Absolute performance differences (Δabs) vs. no-Mθ baselines.
NFT = non-finetuned; FT = MemOp-finetuned.
↑ = gain, ↓ = drop.
| Mθ | LA(1)file | LA(1)func | LA(−1)file | LA(−1)func | SR | LE(1)file | LE(1)func | LE(−1)file | LE(−1)func | Eresolve |
|---|---|---|---|---|---|---|---|---|---|---|
| SE Agent: Devstral-Small-2507 | ||||||||||
| (Baseline) | 69.75 | 62.50 | 64.89 | 51.10 | 39.25 | 32.43 | 27.51 | 27.23 | 15.34 | 10.01 |
| Claude-4-Sonnet | ↑1.50 | ↑1.50 | ↑2.37 | ↑1.01 | ↑2.00 | ↑2.83 | ↑3.13 | ↑3.75 | ↑3.83 | ↑3.74 |
| DeepSeek-1.5B | ↓3.50 | ↓3.75 | ↓2.22 | ↓3.26 | ↓4.50 | ↓3.79 | ↓3.29 | ↓1.56 | ↓1.72 | ↓1.63 |
| DeepSeek-7B | ↓1.75 | ↓1.50 | ↓2.06 | ↓2.65 | ↓3.25 | ↓2.82 | ↓2.53 | ↓0.69 | ↓0.98 | ↓0.42 |
| Qwen2.5-3B | ↓2.00 | ↓2.00 | ↓2.02 | ↓2.50 | ↓4.25 | ↓2.71 | ↓1.87 | ↓2.06 | ↓1.07 | ↓1.03 |
| Qwen2.5-7B | ↓0.50 | ↓1.00 | ↓0.97 | ↓0.97 | ↓1.75 | ↓1.07 | ↓0.84 | ↓0.62 | ↓0.53 | ↓0.68 |
| Qwen3-4B | ↓2.00 | ↓1.25 | ↓1.81 | ↓2.77 | ↓4.00 | ↓2.57 | ↓2.34 | ↓2.41 | ↓1.20 | ↓1.24 |
| Qwen3-4B-T | ↓1.50 | ↓0.50 | ↓1.13 | ↓1.46 | ↓3.25 | ↓1.52 | ↓0.56 | ↓0.60 | ↓0.59 | ↓0.61 |
| DeepSeek-1.5B (FT) | ↑0.75 | ↑0.50 | ↑1.33 | ↑0.63 | ↑0.75 | ↑1.19 | ↑0.65 | ↑1.34 | ↑1.39 | ↑2.20 |
| DeepSeek-7B (FT) | ↑2.25 | ↑3.00 | ↑2.78 | ↑3.01 | ↑4.75 | ↑1.35 | ↑2.70 | ↑2.51 | ↑4.13 | ↑3.81 |
| Qwen2.5-3B (FT) | ↑1.00 | ↑0.75 | ↑1.03 | ↑0.71 | ↑0.75 | ↑0.76 | ↑0.63 | ↑1.04 | ↑0.89 | ↑1.92 |
| Qwen2.5-7B (FT) | ↑2.25 | ↑2.00 | ↑2.35 | ↑4.64 | ↑5.25 | ↑1.74 | ↑2.99 | ↑2.21 | ↑4.01 | ↑2.67 |
| Qwen3-4B (FT) | ↑2.00 | ↑1.25 | ↑2.45 | ↑1.37 | ↑1.75 | ↑2.26 | ↑1.16 | ↑2.49 | ↑3.46 | ↑2.22 |
| Qwen3-4B-T (FT) | ↑2.75 | ↑1.75 | ↑3.48 | ↑1.45 | ↑2.50 | ↑3.17 | ↑3.47 | ↑3.91 | ↑4.78 | ↑4.63 |
| SE Agent: Qwen3-Coder-30B-A3B | ||||||||||
| (Baseline) | 52.75 | 48.50 | 49.06 | 40.42 | 33.75 | 33.25 | 30.29 | 28.69 | 21.06 | 17.96 |
| Claude-4-Sonnet | ↑4.00 | ↑2.75 | ↑4.19 | ↑2.70 | ↑2.25 | ↑5.02 | ↑4.14 | ↑5.07 | ↑4.36 | ↑3.78 |
| DeepSeek-1.5B | ↓4.75 | ↓4.00 | ↓4.31 | ↓1.60 | ↓2.75 | ↓2.47 | ↓2.14 | ↓2.46 | ↓1.92 | ↓2.09 |
| DeepSeek-7B | ↓1.75 | ↓1.50 | ↓1.28 | ↓2.05 | ↓1.75 | ↓1.94 | ↓1.45 | ↓1.07 | ↓1.53 | ↓2.24 |
| Qwen2.5-3B | ↓4.25 | ↓4.00 | ↓4.24 | ↓2.40 | ↓2.75 | ↓2.91 | ↓3.08 | ↓1.93 | ↓2.48 | ↓2.28 |
| Qwen2.5-7B | ↓2.75 | ↓1.25 | ↓1.73 | ↓0.85 | ↓0.75 | ↓0.94 | ↓1.35 | ↓0.97 | ↓1.03 | ↓2.04 |
| Qwen3-4B | ↓4.50 | ↓3.75 | ↓4.33 | ↓2.50 | ↓1.75 | ↓2.98 | ↓2.87 | ↓2.55 | ↓2.29 | ↓2.47 |
| Qwen3-4B-T | ↓3.50 | ↓3.00 | ↓3.19 | ↓0.65 | ↓1.00 | ↓1.61 | ↓1.68 | ↓1.17 | ↓1.21 | ↓1.85 |
| DeepSeek-1.5B (FT) | ↑1.25 | ↑2.50 | ↑2.27 | ↑2.12 | ↑1.25 | ↓0.27 | ↑1.36 | ↑1.83 | ↑1.72 | ↑1.68 |
| DeepSeek-7B (FT) | ↑2.00 | ↑3.00 | ↑3.62 | ↑2.81 | ↑2.50 | ↑3.07 | ↑3.88 | ↑5.04 | ↑2.05 | ↑1.42 |
| Qwen2.5-3B (FT) | ↑0.75 | ↑0.50 | ↑0.94 | ↑0.62 | ↑0.50 | ↑0.19 | ↑1.69 | ↑0.82 | ↑0.82 | ↑0.69 |
| Qwen2.5-7B (FT) | ↑2.50 | ↑3.50 | ↑3.86 | ↑3.56 | ↑3.50 | ↑3.93 | ↑4.37 | ↑5.15 | ↑3.82 | ↑3.61 |
| Qwen3-4B (FT) | ↑2.00 | ↑1.25 | ↑2.37 | ↑1.46 | ↑1.00 | ↑3.03 | ↑2.42 | ↑3.29 | ↑2.09 | ↑1.41 |
| Qwen3-4B-T (FT) | ↑4.25 | ↑3.25 | ↑5.44 | ↑3.21 | ↑2.25 | ↑5.50 | ↑4.80 | ↑5.93 | ↑5.12 | ↑4.10 |
Table 2: Cross-Episode Memory Augmentation
Memory evolves progressively across a sequence of tasks per repository.
NFT = non-finetuned; FT = MemOp-finetuned.
↑ = gain, ↓ = drop.
| Mθ | LA(1)file | LA(1)func | LA(−1)file | LA(−1)func | SR | LE(1)file | LE(1)func | LE(−1)file | LE(−1)func | Eresolve |
|---|---|---|---|---|---|---|---|---|---|---|
| SE Agent: Devstral-Small-2507 | ||||||||||
| (Baseline) | 69.75 | 62.50 | 64.89 | 51.10 | 39.25 | 32.43 | 27.51 | 27.23 | 15.34 | 10.01 |
| Claude-4-Sonnet | ↑0.75 | ↑1.25 | ↑1.47 | ↑0.68 | ↑1.25 | ↑2.35 | ↑2.34 | ↑2.41 | ↑2.07 | ↑2.63 |
| DeepSeek-7B | ↓6.00 | ↓7.25 | ↓4.54 | ↓6.37 | ↓5.25 | ↓8.07 | ↓4.08 | ↓5.47 | ↓3.59 | ↓4.49 |
| Qwen2.5-7B | ↓3.25 | ↓5.25 | ↓2.52 | ↓3.38 | ↓3.50 | ↓4.01 | ↓2.27 | ↓0.61 | ↓2.23 | ↓1.65 |
| Qwen3-4B | ↓5.25 | ↓7.25 | ↓4.05 | ↓6.32 | ↓4.75 | ↓4.78 | ↓2.64 | ↓2.86 | ↓1.96 | ↓1.95 |
| DeepSeek-7B (FT) | ↑1.00 | ↑0.25 | ↑0.48 | ↑0.42 | ↑1.00 | ↑0.64 | ↑0.47 | ↑0.65 | ↑0.39 | ↑0.68 |
| Qwen2.5-7B (FT) | ↑1.25 | ↑1.00 | ↑1.19 | ↑0.86 | ↑2.75 | ↑2.36 | ↑2.74 | ↑1.52 | ↑2.43 | ↑2.73 |
| Qwen3-4B (FT) | ↑1.75 | ↑1.25 | ↑1.69 | ↑0.78 | ↑1.75 | ↑2.28 | ↑1.81 | ↑2.35 | ↑2.59 | ↑1.33 |
| SE Agent: Qwen3-Coder-30B-A3B | ||||||||||
| (Baseline) | 52.75 | 48.50 | 49.06 | 40.42 | 33.75 | 33.25 | 30.29 | 28.69 | 21.06 | 17.96 |
| Claude-4-Sonnet | ↑1.75 | ↑1.50 | ↑1.70 | ↑1.44 | ↑1.25 | ↑1.37 | ↑0.85 | ↑1.92 | ↑1.57 | ↑0.70 |
| DeepSeek-7B | ↓6.25 | ↓7.75 | ↓6.42 | ↓7.16 | ↓4.50 | ↓6.61 | ↓6.63 | ↓6.02 | ↓5.79 | ↓5.18 |
| Qwen2.5-7B | ↓4.25 | ↓3.75 | ↓3.74 | ↓3.53 | ↓2.50 | ↓4.47 | ↓5.11 | ↓3.32 | ↓3.29 | ↓3.85 |
| Qwen3-4B | ↓6.00 | ↓7.50 | ↓6.77 | ↓6.78 | ↓4.25 | ↓5.82 | ↓6.13 | ↓4.98 | ↓4.85 | ↓4.34 |
| DeepSeek-7B (FT) | ↑0.50 | ↑1.25 | ↑1.80 | ↑0.90 | ↑1.75 | ↑0.38 | ↑0.59 | ↑0.55 | ↑1.21 | ↑0.38 |
| Qwen2.5-7B (FT) | ↑1.25 | ↑1.75 | ↑2.26 | ↑1.88 | ↑3.00 | ↑1.21 | ↑1.08 | ↑2.17 | ↑1.92 | ↑1.33 |
| Qwen3-4B (FT) | ↑2.75 | ↑2.25 | ↑3.17 | ↑2.45 | ↑2.50 | ↑2.08 | ↑1.89 | ↑2.15 | ↑2.26 | ↑2.22 |
Generalizability
MemOp generalizes across SE agent backbones, Mθ backbones, repositories, finetuning stages, and RL algorithms. Click a button below to inspect each axis.
Figure 16. Repository-wise generalizability across 9 disparate SWE-Bench repositories (Qwen3-Coder-30B-A3B + MemOp Qwen3-4B-T). MemOp consistently outperforms the no-Mθ baseline with absolute gains of up to ↑17.50% in SR and ↑15.00% in LA. Only 4 out of 90 comparisons show degradation.
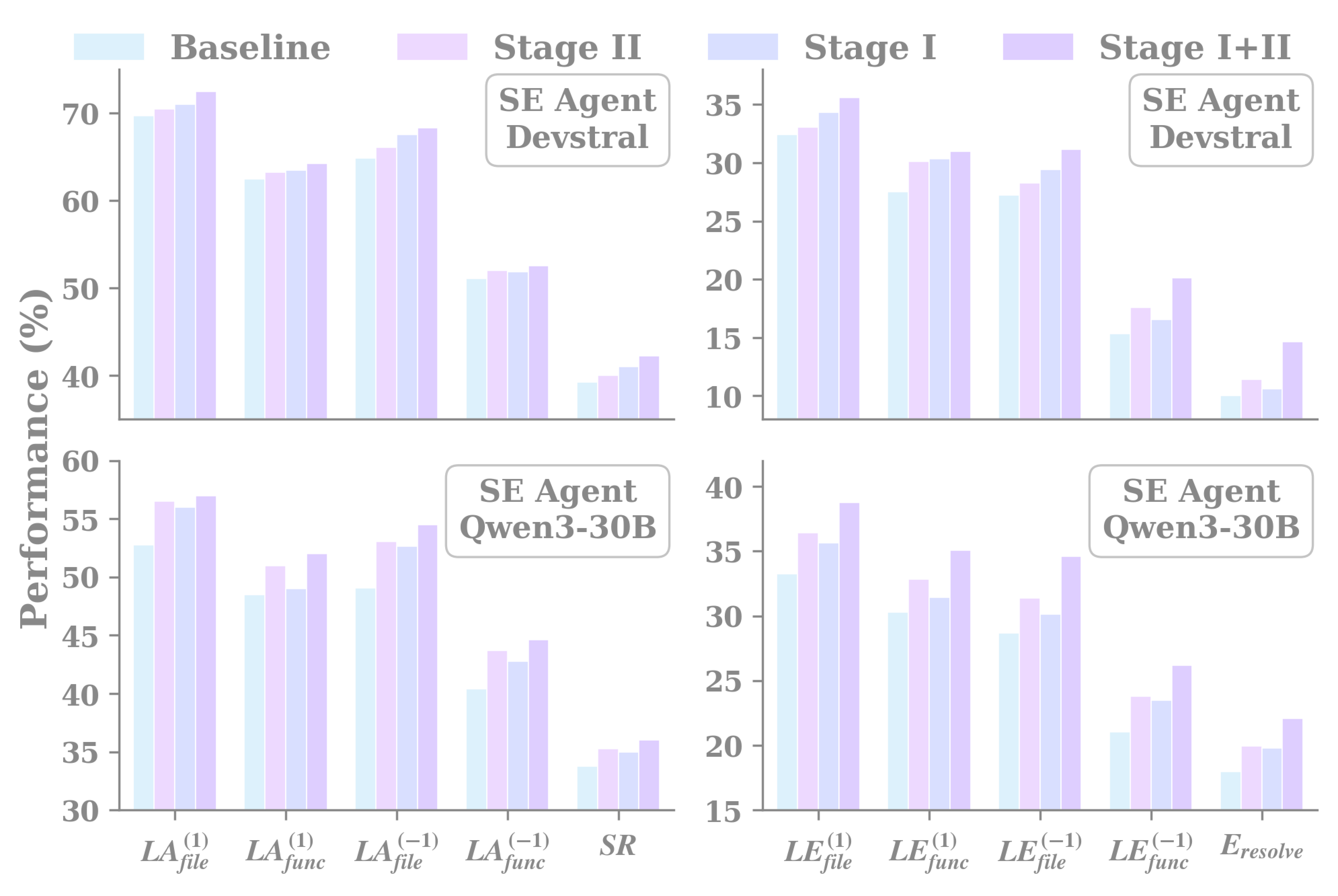
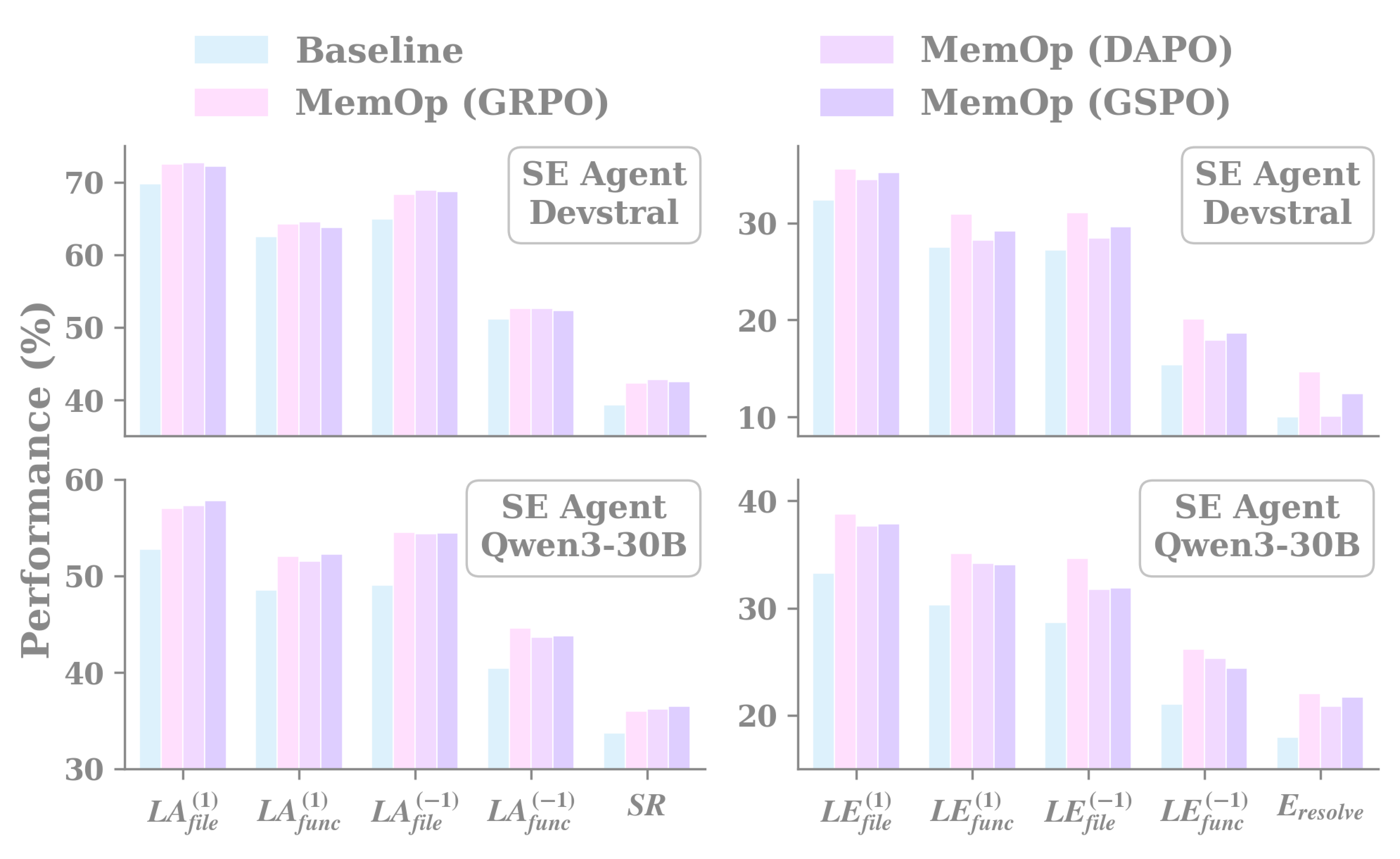
Memory Evolution Granularity: Episode-Level vs Action-Level
A natural question: should memory evolve at the action level or the episode level? We compare both with the same SE agent (Qwen3-Coder-30B-A3B) and Mθ (Qwen3-4B-T).
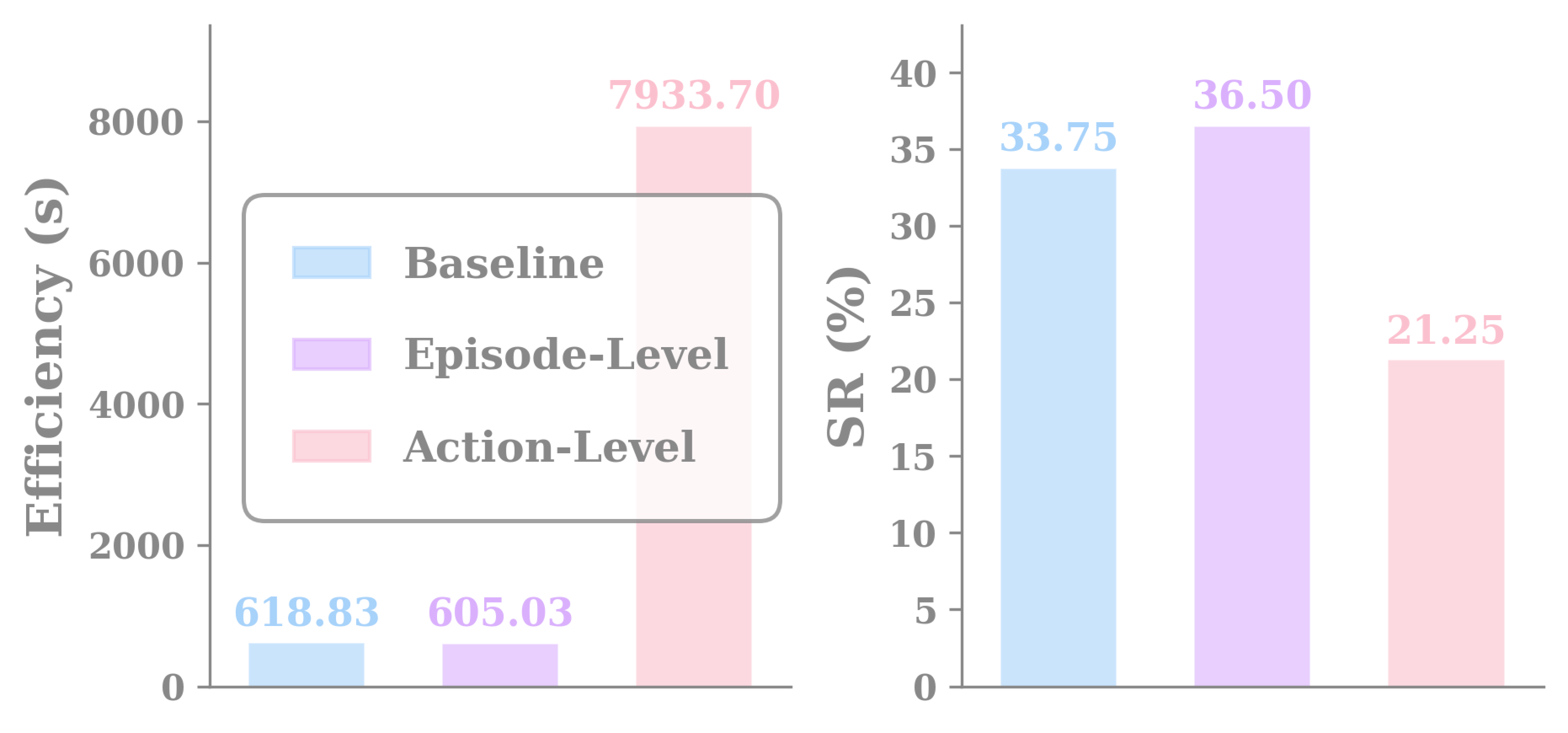
Figure 20. Memory evolution granularity. Episode-level evolution improves SR by ↑2.75% with ↓2.23% relative overhead. Action-level evolution collapses: ↓12.50% SR and up to ×11.82 longer per task — too much memory thrash.
💡 Key Insights
- Reflection alone isn't enough. Non-finetuned Mθ usually hurts SE performance. MemOp's closed-loop optimization is what turns reflection into reliable improvement.
- Memory utility is a learnable signal. Anchoring training to validated downstream impact lets a memory model surpass strong off-the-shelf reflectors (e.g., Claude-4-Sonnet) on multiple metrics.
- Both stages matter. Stage I builds foundational generation; Stage II refines via comparative performance signals. The combination is strictly better than either alone.
- Memory structure matters — readable beats clever. Among nine candidates,
Memory.mdwins (Table 3): structures the SE agent can easily parse are the structures it benefits from most. - Episode-level evolution is the right granularity. Action-level updates collapse (×11.82 slower, ↓12.50% SR). Episode-level updates lift SR by ↑2.75% with lower overhead.
- Robust across different repositories. Show per-repo robustness across different repositories (Fig. 16); maximum gains reach ↑17.50% SR and ↑15.00% LA.
- Cross-episode evolution adds long-horizon value. MemOp accumulates repository-level knowledge across a task sequence while updating only what no longer helps.
- Quality at lower cost. MemOp reduces computational cost by ≥9.79% while improving accuracy, as efficiency comes from the right memory, not more of it.
Resources
Citation
If you find this work useful, please kindly cite:
@article{guo2026memop,
title={Enhancing Software Engineering Through Closed-Loop Memory Optimization},
author={Guo, Xuehang and Wang, Zora Zhiruo and Wang, Qingyun and Neubig, Graham and Wang, Xingyao},
journal={arXiv preprint arXiv:2606.05646},
url={https://arxiv.org/pdf/2606.05646},
year={2026}
}